Blog
Zet uitdagingen vanuit GDPR/AVG om in een kans voor beter en sneller testen!
Geplaatst op 20/05/2020
Door: Gilbert Smulders, Consultant bij ViQiT
De steeds strengere wetgeving inzake gegevens privacy, zoals de Nederlandse wet Algemene Verordening Gegevensbescherming of de General Data Protection Regulation van de EU, heeft testdata een urgent probleem gemaakt voor organisaties over de hele wereld. Het heeft testen stevig op de radar gezet van ‘de business’, die zich nu actief bezighoudt met hoe gegevens worden gebruikt bij zowel het testen als het ontwikkelen.
Dit biedt een kans voor testers. Het huidige bedrijfsbelang – en het bijbehorende budget – biedt een kans om een van de meest omslachtige en tijdrovende testprocessen te verbeteren: het verkrijgen van testdata. Deze verbetering vraagt echter een complete oplossing voor de problemen omtrent tijd en kwaliteit binnen het huidige beheer van testdata.
Een dergelijke oplossing zal worden uiteengezet in het gezamenlijke Curiosity- en ViQiT-webinar; Zet uitdagingen vanuit GDPR/AVG om in een kans voor beter en sneller testen. Daar kunt u zich vandaag nog voor aanmelden. Deze blog geeft een voorproefje op de uitdagingen en oplossingen die worden besproken tijdens de webinar op 24 juni.
Testdata en compliance: inzicht in het risico
Het gebruik van onbewerkte productiegegevens in minder veilige testomgevingen is tegenwoordig riskanter dan ooit.
Ten eerste is het de vraag of het überhaupt mag en wat dan de legitieme gronden zijn voor het gebruik van deze gegevens tijdens testen. Ondertussen blijven menselijke fouten de belangrijkste oorzaak van kostbare datalekken. Het delen van gevoelige informatie tussen testomgevingen verhoogt daarom het risico op schade door datalekken, waarvoor de boetes tegenwoordig honderden miljoenen euro’s kunnen bedragen.
Bovendien hebben organisaties tegenwoordig vaak niet de infrastructuur om alle gegevens van één persoon betrouwbaar te lokaliseren in hun complexe uitgestrekte landschap. Dit maakt het bijna onmogelijk om een kopie van de informatie van die persoon op verzoek te verwijderen of inzichtelijk te maken, wat in strijd is met privacy richtlijnen.
Maskeren van productiedata: geen complete oplossing
De eenvoudigste manier om enorme boetes en merkschade te voorkomen, is door de toegang tot gevoelige informatie in de hele organisatie te beperken. Het maskeren van productiegegevens voordat deze naar testomgevingen worden overgehaald, is daarom voor de meeste organisaties een minimale eis.
De uitdaging hierbij is dat het anoniem maken van productiegegevens vaak traag en complex is. Hierdoor vervang je compliance kwesties door knelpunten in het testproces. Je vervangt dus de ene testuitdaging door een andere.
Problemen bij het verstrekken van testdata ontstaan doordat het maskeren van complexe gegevens uit verschillende bronnen inherent complex is. De complexe relaties binnen en tussen databronnen moeten behouden blijven, ook als gevoelige informatie wordt verwijderd.
Het handmatig maskeren van gegevens zorgt daarom voor een knelpunt binnen het leveren van testdata. Het laat ‘parallelle’ testteams en data-hongerige testautomatisering frameworks ongeduldig wachten op een beperkt aantal verouderde kopieën van gegevens. Daardoor wordt het onmogelijk om het nieuwste systeem binnen één iteratie operationeel te krijgen.
Maskeren doet bovendien verder niets om de verscheidenheid aan productiegegevens te verbeteren, waardoor uitschieters en onverwachte resultaten gemist worden die nodig zijn voor een grondige test. Testers kunnen op hun beurt slechts een fractie van de testen uitvoeren die nodig zijn voor voldoende testdekking. Daardoor worden systemen potentieel blootgesteld aan kostbare en schadelijke bugs in de productie.
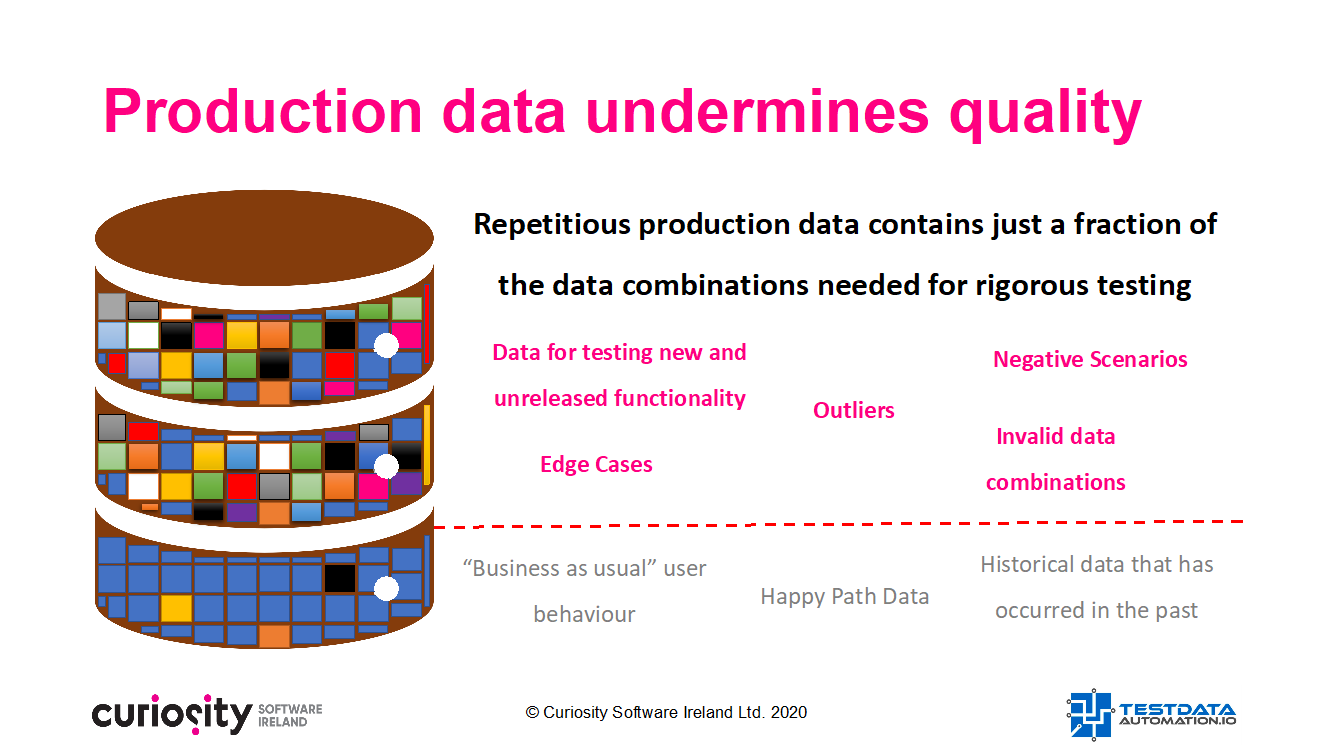
Het handmatig maskeren en overhalen van productiegegevens naar testomgevingen creëert zodoende een bottleneck. Het tast de snelheid en kwaliteit van testen aan. Dit is in strijd met de principes van continu testen die binnen DevOps en Agile vaak gehanteerd worden. Testen binnen kort-cyclische iteratieve levering en geautomatiseerde testuitvoering vereisen daarom een nieuwe aanpak.
Zet uitdagingen om in een kans voor beter en sneller testen
Grondig testen binnen kort-cyclische iteratieve levering en geautomatiseerde testen vereisen constante toegang tot een uitgebreide set aan testdata. Data om elke gewenste positieve en negatieve test uit te voeren. Precies beschikbaar waar en wanneer testers en testautomatisering frameworks die nodig hebben.
Een testdata strategie vandaag de dag moet daarom verder gaan dan de logistiek van een centraal team dat gegevens langzaam naar testomgevingen kopieert. Testdata mag niet langer op deze manier gewoon worden beheerd, maar moeten in plaats daarvan op een manier beschikbaar worden gesteld die de testsnelheid en -kwaliteit verbetert.
Het beschikbaar maken van deze “agile testdata” is nu mogelijk met het nieuwe toonbeeld in testdata technologie: “Test Data Automation”. TDA standaardiseert testdatamanagementprocessen en maakt data op aanvraag herbruikbaar binnen geautomatiseerde testen en CI/CD-pijplijnen. Testers kunnen het opnemen in herbruikbare processen voor zowel geautomatiseerde als handmatige testen. Het vinden en maken van complete testdata sets terwijl testen worden gegenereerd of uitgevoerd:
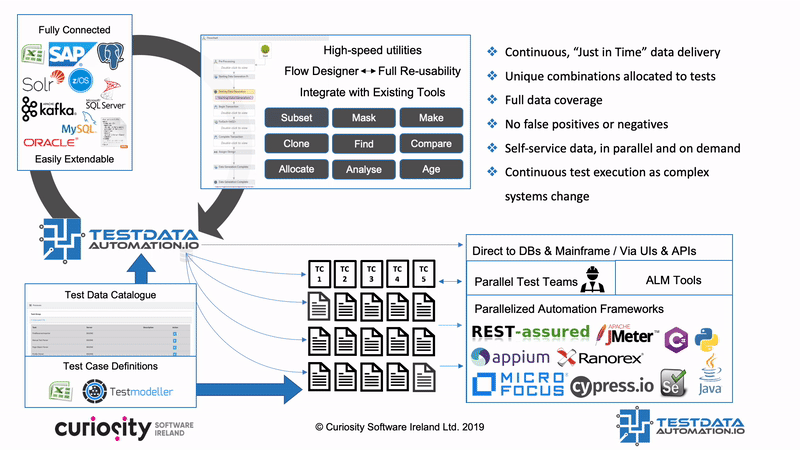
Deze testdata benadering gaat verder dan logistiek en compliance. Het maakt een moderne benadering mogelijk voor testdata:
- Conform; gegevens maskeren als deze worden gevonden en toewijzen aan exacte testgevallen.
- Gebouwd voor kwaliteit; het genereren van ontbrekende gegevenscombinaties zodat unieke datasets beschikbaar worden gemaakt voor bepaalde testsituaties.
- Selfservice en op aanvraag; het activeren van herbruikbare data processen vanuit een selfserviceportal of opgenomen in geautomatiseerde testen en CI / CD-processen.
- Parallel; het produceren van unieke gegevenscombinaties voor iedere test om conflicten tijdens testuitvoering te voorkomen en team overstijgende afhankelijkheden te verminderen.
Klinkt het interessant? Kom dan zelf kijken. Doe met Curiosity en ViQiT mee op 24 juni om het nieuwe toonbeeld in testdata te ontdekken.
IN ENGLISH:
Turn GDPR Compliance into an Opportunity for Better, Faster Testing
Ever-tighter data privacy legislation like the EU General Data Protection Regulation and The California Consumer Privacy Act has made test data a pressing problem for organisations worldwide. It has put testing firmly on the radar of ‘the business’, who are now actively concerned with how data is being used in both testing and development.
This presents an opportunity for QA. The current business concern – and its associated budget – offers a chance to transform one of the most cumbersome and time-consuming testing processes: test data provisioning. However, this transformation requires a complete solution to the time and quality issues associated with current test data management.
Such a solution will be set out on the joint Curiosity and ViQiT webinar, Turn GDPR Compliance into an Opportunity for Better, Faster Testing. You can sign up for that today. This blog provides a flavour of the challenges and solutions that will be discussed live on June 24th.
Test data and compliance: understanding the risk
Using raw production data in less secure test environments is today riskier than ever.
Firstly, it raises questions around consent and the legitimate grounds for processing data in QA. Meanwhile, internal human error remains the number one cause of costly data breaches. Sharing sensitive information across test environments therefore increases the risk of damaging data breaches, for which the fines today can be in the hundreds of millions.
Organisations today furthermore often lack the infrastructure to locate one person’s data reliably across sprawling test environments. This makes it near-impossible to delete or share a copy of that person’s information on demand, potentially breaching both an EU Citizen’s Right to Erasure and to Data Portability.
Masking production: Not a complete solution
The simplest way to avoid massive fines and brand damage is to limit access to sensitive information across the organisation, and masking production data before it moves to test environments is therefore a minimum for most organisations.
The challenge is that anonymising production data can be slow and complex. This in turn replaces compliance concerns with QA bottlenecks, swapping one set of testing challenge for another.
These bottlenecks in data provisioning arise because masking complex data from numerous sources is inherently complex. The relationships and complex trends that exist within and across data sources must be retained, even as sensitive information is removed.
Manually masking data therefore creates a bottleneck in test data provisioning. It leaves ‘parallel’ test teams and data-hungry automation frameworks waiting idly for a limited number of out-of-date copies of data, making it impossible to the latest system within an iteration.
Masking furthermore does nothing to improve the variety of production data, which lacks the outliers and unexpected results needed for rigorous testing. QA can in turn only execute a fraction of the tests needed for sufficient test coverage, exposing systems to costly and damaging bugs in production.
Manually masking and moving production data to test environments accordingly creates a dependency and bottleneck. This undermines testing speed and quality, and conflicts with the principles of continuous testing, DevOps, and “Agile”. Testing at the speed of iterative delivery and automated test execution demands a new approach.
Turn Compliance into an Opportunity for Better, Faster Testing
Rigorous testing at the speed of iterative delivery and automated testing requires constant access to comprehensive test data. That means data with which to execute every positive and negative test, available exactly when and where testers and automation frameworks need it.
A test data strategy today must therefore move beyond the logistics of a central team copying data slowly to test environments. Test data should no longer simply be “managed” in this way, but must instead be made available in a way that improves testing speed and quality.
Providing this “agile test data” is possible with the new paradigm in test data technology: “Test Data Automation”. TDA standardizes test data management processes and makes them re-usable on demand within automated testing and CI/CD pipelines. Testers can embed in the re-usable processes in both automation and manual testing, finding and making complete test data as tests are generated or executed:
This approach to test data moves beyond the logistics of compliance. It enables a modern approach to test data that is:
- Compliant, masking data as it is found and allocated to exact test cases.
- Built for quality, generating missing data combinations as unique data sets are found and made for a particular test suite.
- Self-service and on demand, triggering re-usable data jobs from a self-service portal or embedding them within automated testing and CI/CD processes.
- Parallelized, producing unique data combinations for each test to avoid clashes during execution and cross-team constraints.
Sound interesting? Come and see for yourself. Join Curiosity and ViQiT on June 24th to see the new paradigm in test data.